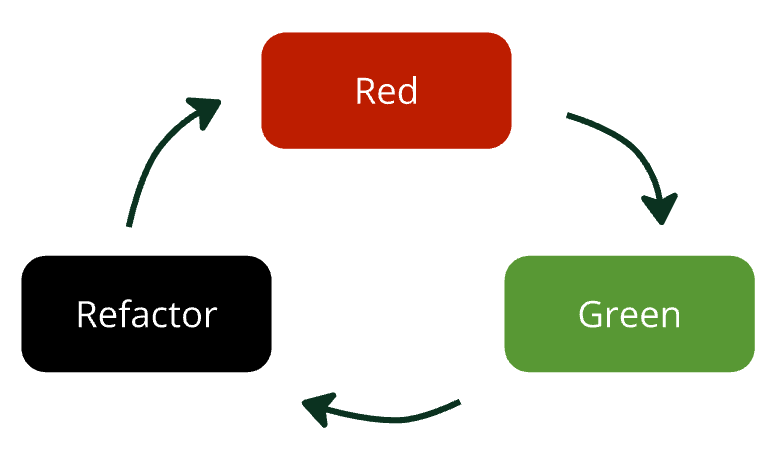
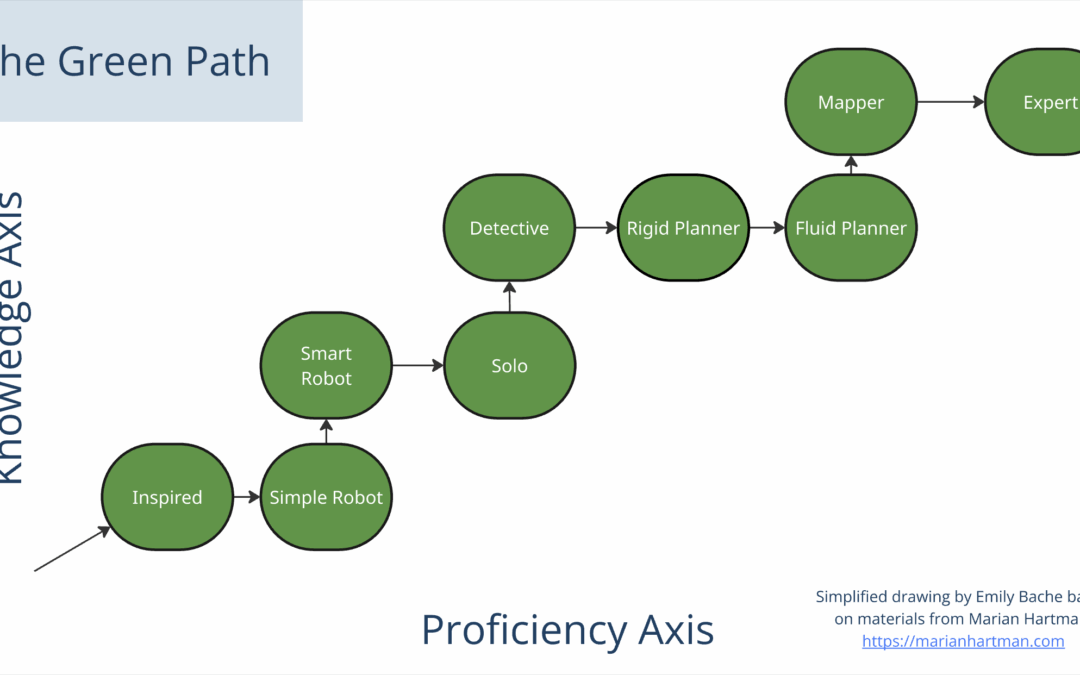
This post is available as a video on the Modern Software Engineering Channel The focus of technical coaching is the minute-by-minute habits that software developers need to create good quality working software that lasts. These days all the teams I meet are asking for...

I Stopped Coding and Started Architecting Agents (And Why You Should Too)
read more