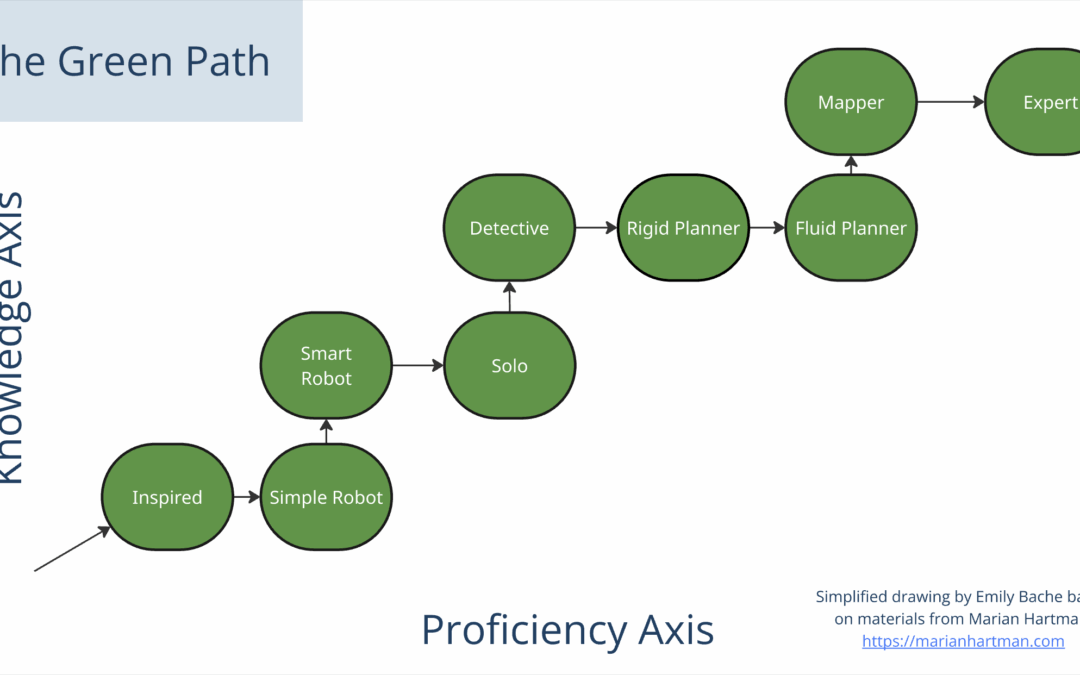
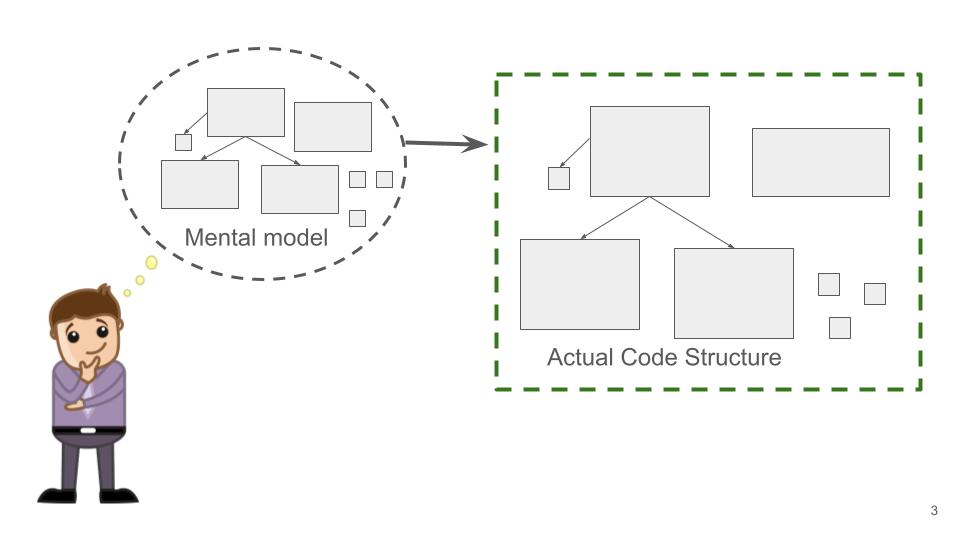
A coding revolution has happened, just in the past few months. Augmented coding is working so well, almost everyone I know has adopted it. I’ve spoken to half a dozen or more different technical coaches in the past couple of weeks, all of whom I know were excellent...
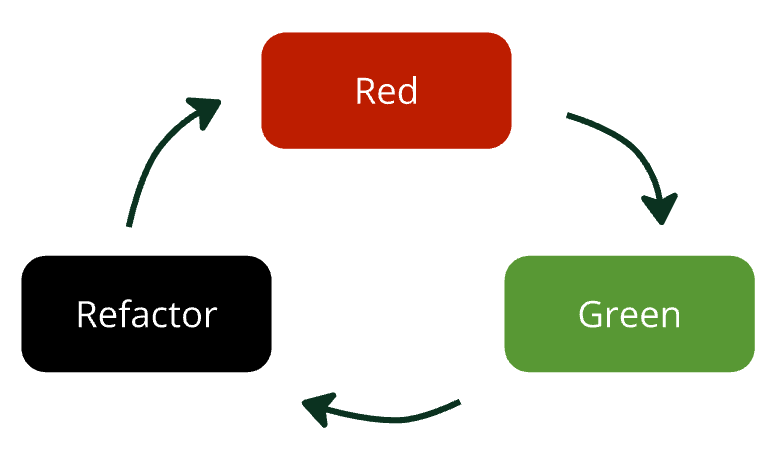
Test-Driven Development with Agentic AI
read more