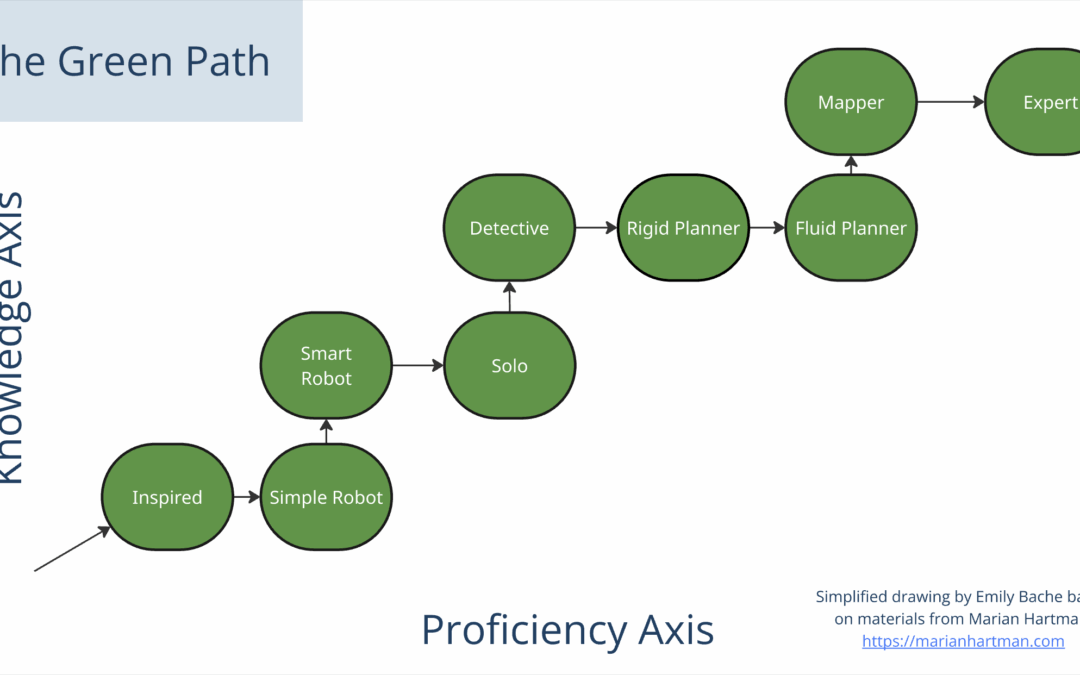
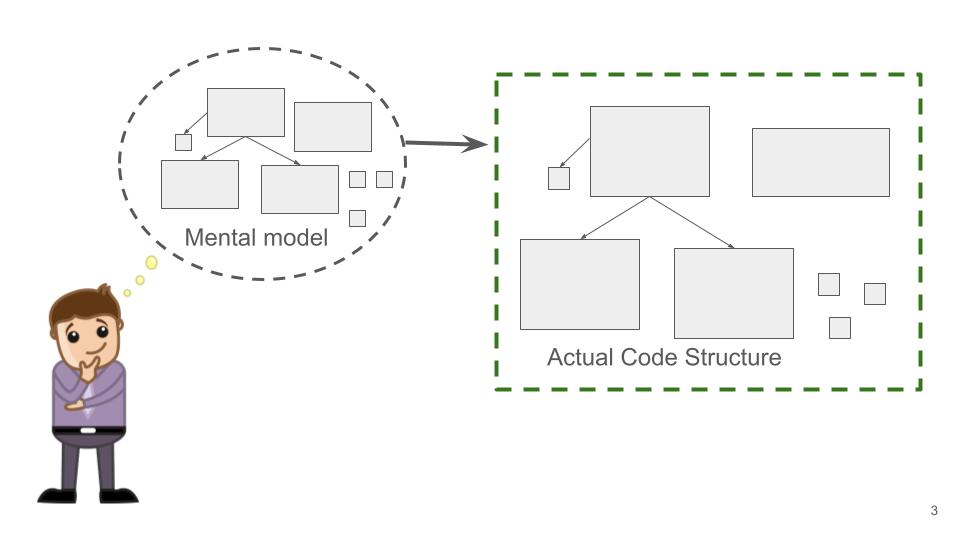
This is a companion post to my video with the same title. Whether you’re using an AI tool to write them or not, you need tests. If you’re doing Continuous Delivery, the tests in your pipeline are essential to determine releasability. Unfortunately, it’s often a source...
Seven Testing Myths Every Developer Should STOP Believing
read more