On Saturday I was up in Stockholm facilitating my fourth code retreat for Valtech, and my second Global Day of Code Retreat. It seemed to go very well. I tried out a few new elements, which seemed to make it go even better than the previous ones, so I thought I’d talk about them here in my blog.
The first thing we changed was that we had quotas for men and women, and we were aiming for a 50/50 gender balance. About a month before the code retreat, we were fully booked, with 20 places each for men and women taken. In the end several people dropped out at the last minute, and there were slightly more men. Still, it was a much better balance than last year. I think it made for a healthier atmosphere during the day, and we encouraged more women to be active in the community generally.
The second thing we changed was I didn’t require people to do Game of Life, I suggested some other code katas as alternatives. Game of Life is an excellent kata for practicing skills like writing clean code, simple design, and TDD generally. It’s also really fun to be doing an excercise that thousands of other programmers are also working on. However, I realized that around 1/3 of the people who’d signed up for the event had already been to a previous code retreat, and might be getting bored with Game of Life. We’re there to have fun, after all!
As I’ve been working on my book, and running various coding dojos recently, I’ve been thinking hard about TDD and how to learn it. It’s a multifaceted skill, and some katas allow you to focus on particular aspects of it, which can make practice more rewarding. For a complete beginner to TDD, Game of Life is actually quite hard to get started with, I’ve seen a lot of people struggling with it. So in my introduction I highlighted four other katas people could choose from, as well as Game of Life:
- String Calculator – good for the TDD newbie, since it really leads you by the hand
- Tennis – good for practicing refactoring
- GildedRose – good for practicing writing really good tests (and refactoring)
- TyrePressure – good for understanding SOLID principles
People seemed to generally appreciate having a choice. Some pairs chose a String Calculator for their first couple of sessions, to get used to TDD, then went on to Game of Life for the others. Some pairs tried out Tennis, Gilded Rose and Tyre Pressure in the afternoon, instead of one of the other challenges. Some pairs who were already good at TDD tried out String Calculator in Clojure, and found it let them concentrate on the learning the language not solving the problem. One person, (who has been to 3 code retreats previously), didn’t do Game of Life all day, and said he really enjoyed himself and learnt loads!
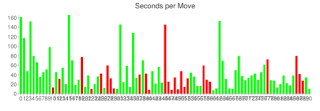
The third thing we changed was that I suggested people try cyber-dojo as a coding environment. This is a tool designed by Jon Jagger as an aid to practicing your coding skills. It provides a basic editor/testing environment, and records the state of the code every time you run the tests. You can review all your changes in the session retrospective, and get a picture of how well your TDD was going.
Before the code retreat, I had set up cyber dojos for Game of Life, and Tennis. I put up the cyber-dojo ids on the whiteboard, and through the day most of the pairs tried it out for one or more sessions.
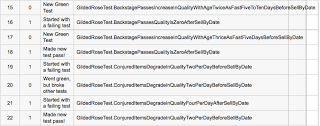
As a facilitator, I found it really helpful when going up to a pair, to be able to see the little row of traffic light symbols at the top of their screen. I could quickly get an overview of how their session was going. For example, if I see a few red-green-yellow sequences then I can infer they are probably doing ok at TDD. If I can see nothing bug a long string of yellow, then I know they’re in trouble!
For the pairs, some liked cyber-dojo because it meant they didn’t waste any time setting up their coding environment at the start of the session. For those doing Tennis, if they made a refactoring mistake, they could very easily just click on the most recent green traffic light to revert back to a known good state, and practice doing the refactoring again. Some pairs found it helpful in the retrospective to review their session in the tool.
Other pairs didn’t get on so well with cyber-dojo. Some couldn’t live without their usual editor commands. Some got confused by the lack of syntax highlighting. A couple found a bug in cyber-dojo that it lost touch with the server and stopped updating their test results, whatever they did to the code. (The workaround is to open the same url in a new window, btw).
I know Jon is aware of this bug, and I’m sure he’ll track it down, but actually the lack of syntax highlighting and editor commands is deliberate. It’s the same idea as the other challenges, like mute pairing etc – to throw you out of your comfort zone and make you really concentrate on the way you code.
So that was the three things we changed – gender balance, other katas, cyber-dojo. What we didn’t change was the overall format or aims of the day. We still paired for 5 sessions of 45 minutes, and threw away the code afterwards. We still had coding challenges like “Mute pairing with find the loophole” and “Maximum 4 line methods”, and held retrospectives after every session. I think deliberate practice in a group is at the core of what makes Code Retreat (and coding dojos!) fun and valuable. The changes we introduced were all designed to enhance the learning experience, and were based on experience and reflection after previous events.
Overall I was very pleased with all the changes we introduced, and I’d like to do it like that again. If you’re facilitating or organizing a code retreat, perhaps you’d like to introduce some of these elements too.