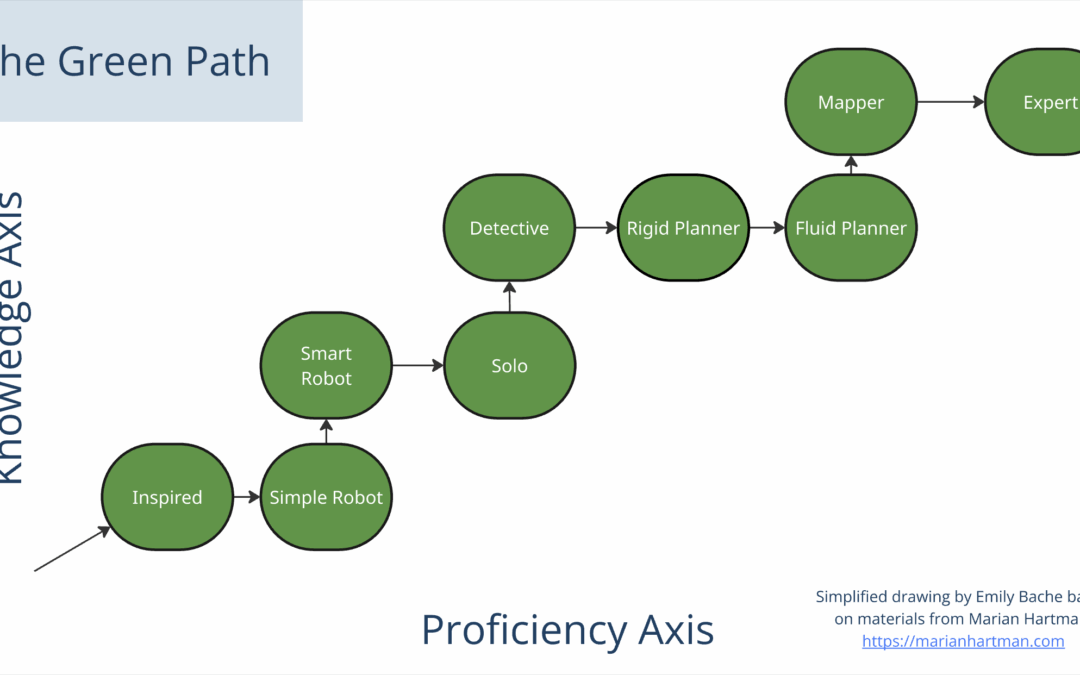
by Emily Bache | Dec 19, 2025 | Coding Skills
Refactoring is one of the most impactful skills I teach in my work as a Samman Technical Coach. I do a lot of Learning Hour training sessions to teach particular refactorings. Sometimes these sessions go better than others, and until now I was improving them only...
by Emily Bache | Apr 21, 2025 | How-to
Collaborative coding can be a fantastic forum for getting stuff done at the same time as learning programming techniques and getting to know other developers. I’ve been enjoying the recent Samman Society Ensemble sessions where we work on our website...
by Emily Bache | Oct 10, 2016 | Code Kata
I’ve been favouring an Approval Testing approach for many years now, since I find it pretty useful in many situations, particularly for acceptance tests. Not many people I meet know the term though, and even fewer know how to use the technique. Recently...
by Emily Bache | Jun 2, 2015 | Code Kata
I’ve been interested for a while in the relationship between TDD and good design for a while, and the SOLID principles of Object Oriented Design in particular. I’ve got this set of 4 “Racing Car” exercises that I originally got from Luca...
by Emily Bache | Apr 14, 2015 | Code Kata
Recently I became intrigued with something Seb Rose said on his blog about ‘recycling’ tests. He talks about first producing a test for a ‘low fidelity’ version of the solution, and refining it as you learn better what the solution should look...
