
A coding revolution has happened, just in the past few months. Augmented coding is working so well, almost everyone I know has adopted it. I’ve spoken to half a dozen or more different technical coaches in the past couple of weeks, all of whom I know were excellent engineers using TDD in the before-times, and have all told me these days they write almost no code by hand. It’s an enormous shift, seeing as the first agentic coding tools only came out a year ago.
This article is an attempt to work out what good engineers are doing today and how it is different from the past. If the AI writes both the code and tests together, is it even TDD? Has anything been kept? I’ve been gathering anecdotes about how people are tackling all the aspects of coding that were previously part of TDD.
There is quite a lot of variation in the exact practices, so here I’m first going to describe the majority case, then in a second section talk about the main variations. It’s surprising how much is different as well as how much is the same as in classic TDD.
How do you create a Test List?
In classic TDD, when you start coding on a new user story, there will have been a previous conversation with stakeholders, perhaps a discovery workshop, but definitely a conversation. Then based on your understanding, you create a test list sketching out the examples and edge cases you think you’ll need to cover. It’s a way to slice up the problem and identify concrete examples that will become test cases.
With agentic AI people are still creating this test list, but usually in the form of a markdown “spec” document rather than notes on a piece of paper or sketch on a whiteboard. The AI tool is helping to write this, generating examples and co-creating a plan. A few people said the pieces on the list are bigger than before. There is certainly more detail and more grammatically correct whole sentences than you’d have seen on a test list previously.
One of the key characteristics of TDD is that the test list gets updated during coding, as you learn more about the problem and the implementation and you discover cases that need to be added or removed. This is part of how TDD enables emergent design and lets the tests drive the development.
In the same way as they would keep a paper test list updated, the TDD practitioners I spoke to were also updating their ‘spec’ during development, with the agent making the edits.
What is a step?
In classic TDD, we talk about three actions: write a failing test (red), write the code to make it pass (green), then refactor. There is a picture of this at the top of the article. If you think about it as a state diagram instead though, there are two states: tests passing, and tests failing. It takes a ‘red’ and a ‘green’ action to get back to passing tests, so together they make a step (aka increment). Each ‘refactor’ action is also a step, so a TDD cycle is actually a red/green step followed by one or more refactor steps.
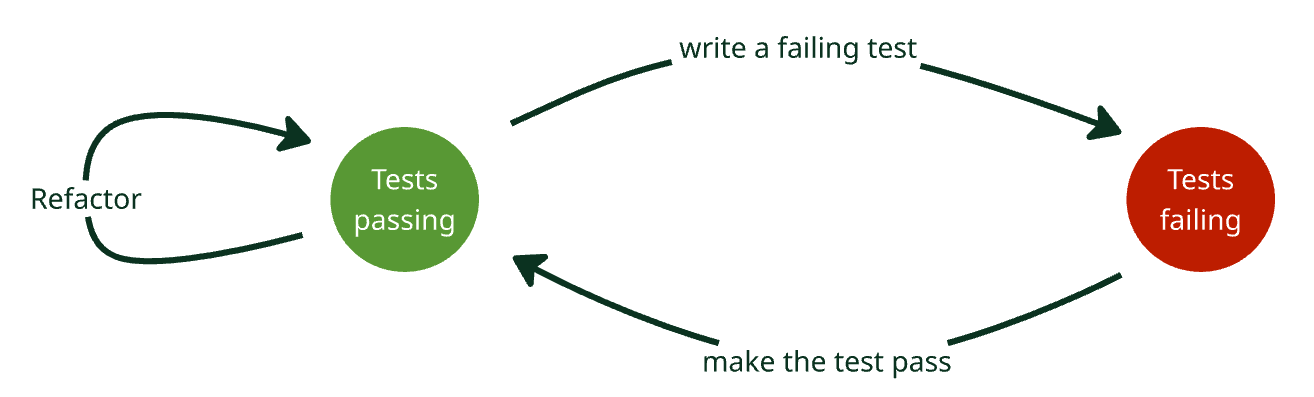
This distinction is interesting because agentic AI seems to have difficulty doing ‘red’ and ‘green’ separately in that order – most people I talked to seem to combine them into the same prompt. I speculate this is because the training data of the agents includes almost no examples of code at the end of the ‘red’ action – because the code is not checked in when tests are failing.
This means the axiom of TDD that you write the test before the functionality it’s supposed to test, doesn’t happen explicitly. We’ve always said how important this is, because it enables you to not tie the test too tightly to the implementation. You also get design feedback on how usable and testable your chosen API is. If you write the tests and code together, you need to include other mechanisms to ensure those desirable outcomes, which I will come to.
How long are steps?
In a classic TDD process you see passing tests every few minutes. Most practitioners would be worried if they had been coding for more than about 15-20 minutes without seeing them pass, and likely revert back to the latest green and start over if that happened. Short cycles are the norm, and while refactoring, it’s more usual for only seconds to go past between green test runs.
All the practitioners using agentic AI reported steps being the same or even shorter than they were before. Most are committing really frequently, loads of tiny changes coming in every few minutes.
Some people are using steps a little longer than that, although still no longer than in classic TDD. This means more lines of code are changed in each step. It seems to me this process is tending towards driving everything from the outer loop acceptance tests rather than sticking to one unit test per cycle.
Is any code written by hand?
Not really! The agent writes it all. A more interesting question is whether people are reading the code the LLMs produce, and for most of the TDD practitioners I spoke to, they absolutely are. Code quality is still a major concern. Both humans and LLMs have an easier time if the code is well structured – it’s important for the long-term maintainability of the project. It is a big challenge though, when these tools can produce a great deal of code changes in a short amount of time. Reviewing every change is easier if you take short steps with a small volume of changes in each one.
The other reason to read the code is to avoid ‘cognitive debt’ – where you lose the big picture of the design and become unable to reason about how to change it safely. The people I spoke to weren’t seeing big problems with this, at least not yet. More on that in a moment.
Additional steps that weren’t in your TDD process before?

Everyone agreed that improving the agent’s ‘harness’ is important. The analogy is with a horse and cart – the LLM is the horse, and the work you want it to do is the cart. The ‘harness’ is all the constraints you put around the LLM to ensure it follows your instructions and moves the cart forwards. In practice this means creating or updating markdown files describing ‘skills’ and processes, as well as linter rules and configuration of other deterministic tools that are part of the prompting and review process.
Several people noted they were routinely bringing in techniques that they had only used infrequently before, like mutation testing, formal methods, property-based testing, security reviews and approval testing. The ‘refactor’ step is often initiated by the agent responding to these additional sources of feedback.
One person mentioned that the coding process has become more intense and they need to spend more time than previously away from the computer to think deeply about the problem. That sounds like a healthy attitude to the power of these tools – make sure you have enough time to think!
Is the code and tests you end up with just as good as before?
With AI, the usual problem is it produces dreadful code – bloated, overdesigned, re-inventing the wheel instead of using libraries: it makes all the worst design mistakes of a junior developer. The TDD practitioners I spoke to reported that the quality they get in the end is as good or even better than they would have written by themselves. That’s impressive, actually – these people have very high standards!
There are several design benefits you expect from TDD specifically, and I’ve noted in this list which part of the TDD workflow contributes most to this quality attribute:
- Well-designed and usable APIs with examples of use in the form of unit tests. (red)
- Good regression tests covering all the important scenarios, (test list), which are not tied too tightly to the implementation and allow refactoring. (red)
- Avoiding overdesign and generic code that does more than you need (green)
- Well designed, readable code that uses the language of the problem domain (test list, refactor)
As previously mentioned, agentic AI will usually combine the red and green steps which could mean you get worse code and tests.
In practice it seems you get most of the benefits of the ‘red’ action through the process of slicing the problem small and writing prompts that really express your intent about outcomes for the code. The agent might not be using the test explicitly to drive low level design, but your prompt is written in the language of the problem. That leads to code that expresses the domain, and tests that are written in terms of user outcomes rather than implementation details.
Doing ‘the simplest thing that could possibly work’ is the mantra for the ‘green’ step – focus only on doing what’s needed by the test. If you don’t do this as a separate step then overdesign can be a problem. Many developers are adjusting this kind of thing in the refactoring step. I speculate that as the agents get a stricter harness and better refactoring tools then they will avoid this problem.
Main variations
Even amongst half a dozen highly skilled engineers there are variations on the TDD process I described above. At the moment I’m not sure if this is because “the future is here, it’s just unevenly distributed” or if it’s personal style, or something else.
A couple of people I spoke to are still prompting the agent to create tests first, in a separate action before coming up with the implementation. They are working in even more fine-grained steps than others, prompting every unit test. This helps eliminate overdesign, helps spot missing test cases, and leaves the developer with a detailed mental model of the code.
Both this group and those doing a red/green combined step report very high code quality in the end. It seems to me the additional benefit from splitting red and green is perhaps you will have less problem with cognitive debt down the line. Cognitive debt is a problem where you no longer have a ‘theory’ in the sense that Peter Naur describes, and it becomes difficult to change the code. (I wrote previously about this in my article “What is more important to learn – Design or Coding?“)
The other big variation I noticed is that not everyone is reading the code. One group has stopped caring about code quality, and see the ‘spec’ as the new source code and the LLM being the compiler. They iterate carefully on a description of what the code should do, and include a huge amount of detail in various markdown files. The other group in contrast is still deeply concerned about code quality, but are using other means to ensure it. Instead of reading the code, they use a battery of linters, static analysis and testing tools, complemented by LLM generated code reviews.
As I mentioned earlier, if you don’t read the code then that will potentially cause cognitive debt. I think it may just be too soon to judge how big of a problem that is. It seems to be the kind of thing that grows over time and isn’t noticeable at first.
Conclusions
The tools and details have changed but I think all these practitioners are doing something that is still recognizably TDD. Yes, most are not strictly writing the tests first, but the process is still centered on small steps, reacting to feedback from the tests, and engineering a setup that delivers high quality code that is possible to change safely.
Finding out about the new ways people are using agentic AI to get even more valuable feedback, even more frequently, is very encouraging. As someone who’s been teaching TDD these past 20 years or so, I’m going to need to make some changes in my specific advice, and I have a lot of teaching materials to review and update! Overall though this is very exciting. I see many opportunities to help developers access a powerful approach to get more done with even higher quality than before. Let’s all continue to follow the old XP maxim: Embrace Change.
Acknowledgements
With many thanks to everyone who talked to me about TDD with agentic AI and who reviewed early drafts of this article:
- Nitsan Avni
- Lars Eckart
- Willem van den Ende
- Llewellyn Falco
- Lada Kesseler
- Johan Martinsson
- Gregor Riegler
- Ivett Ördög





