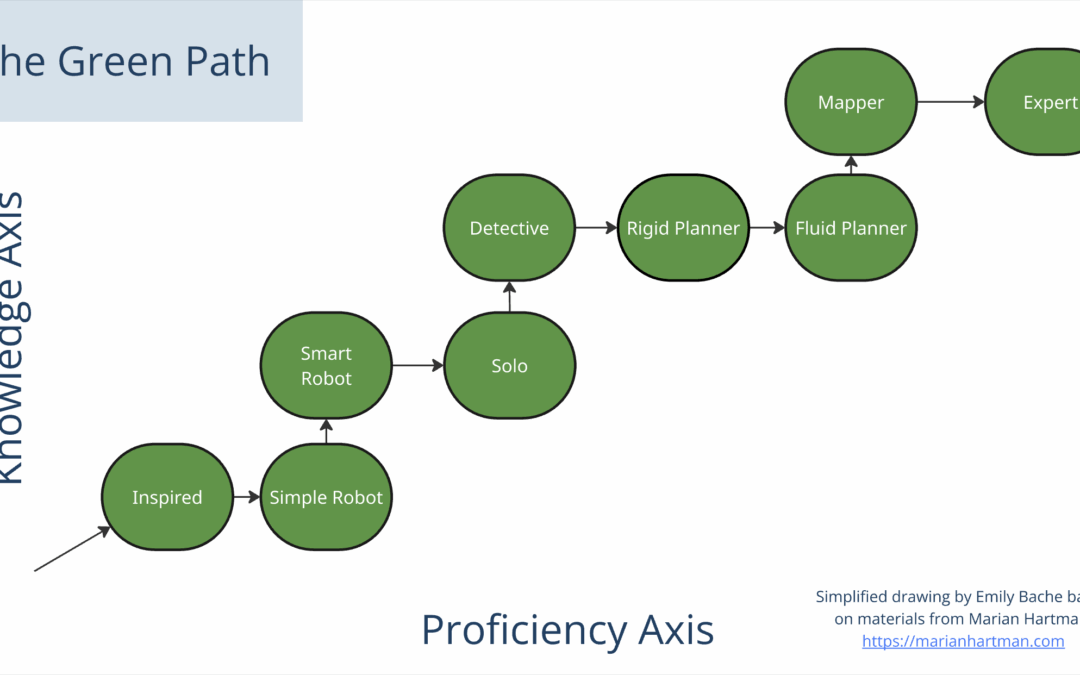
by Emily Bache | Dec 19, 2025 | Coding Skills
Refactoring is one of the most impactful skills I teach in my work as a Samman Technical Coach. I do a lot of Learning Hour training sessions to teach particular refactorings. Sometimes these sessions go better than others, and until now I was improving them only...
by Emily Bache | Nov 8, 2019 | Code Kata
Note: this article was first published on Praqma’s blog Writing tests for ‘Theatrical Players’ When I read Fowler’s new ‘Refactoring’ book I felt sure the example from the first chapter would make a good Code Kata. However, he didn’t include the code for the...
by Emily Bache | Nov 4, 2013 | Experience Report
I was recently at the Software Craftsmanship Conference at Bletchley Park in the UK. This is a one-day conference for software developers, attended by around 150 programmers. All proceeds from the event go to support Bletchley Park, which is of historical interest to...
by Emily Bache | Mar 19, 2013 | Coding Skills, Conference information
I’ve been working on this Kata “Gilded Rose” at a few different coding dojos lately. There is even a video of a session I did at the “Tampere Goes Agile” conference recently. In the video, you can see me talking about my Principles of...
by Emily Bache | Jan 10, 2013 | How-to
The Cyber-Dojo tool was designed by Jon Jagger as en environment where you can practice your coding skills. I’ve used it a few times now with groups at coding dojos and code retreats, and I think it’s a pretty useful tool for those contexts. (See also my...
