Programmers have a vested interest in making sure the software they create does what they think it does. When I’m coding I prefer to work in the context of feedback from automated tests, that help me to keep track of what works and how far I’ve got. I’ve written before about Test Driven Development, (TDD). In this article I’d like to explain some of the main features of Text-Based Testing. It’s a variant on TDD, perhaps more suited to the functional level than unit tests, and which I’ve found powerful and productive to use.
The basic idea
You get your program to produce a plain text file that documents all the important things that it does. A log, if you will. You run the program and store this text as a “golden copy” of the output. You create from this a Text-Based Test with a descriptive name, any inputs you gave to the program, and the golden copy of the textual output.
You make some changes to your program, and you run it again, gathering the new text produced. You compare the text with the golden copy, and if they are identical, the test passes. If the there is a difference, the test fails. If you look at the diff, and you like the new text better than the old text, you update your golden copy, and the test is passing once again.
Tool Support
Text-Based Testing is a simple idea, and in fact many people do it already in their unit tests. AssertEquals(String expected, String actual) is actually a form of it. You often create the “expected” string based on the actual output of the program, (although purists will write the whole assert before they execute the test).
Most unit test tools these days give you a nice diff even on multi-line strings. For example:
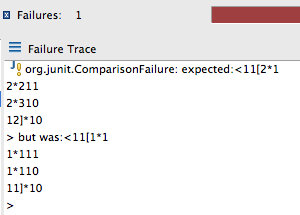

Which is a failing text-based test using JUnit.
Once your strings get very long, to the scale of whole log files, even multi-line diffs aren’t really enough. You get datestamps, process ids and other stuff that changes every run, hashmaps with indeterminate order, etc. It gets tedious to deal with all this on a test-by-test basis.
My husband, Geoff Bache, has created a tool called “TextTest” to support Text-Based testing. Amongst other things, it helps you organize and run your text-based tests, and filter the text before you compare it. It’s free, open source, and of course used to test itself. (Eats own dog food!) TextTest is used extensively within Jeppesen Systems, (Geoff works for them, and they support development), and I’ve used it too on various projects in other organizations.
In the rest of this article I’ll look at some of the main implications of using a Text-Based Testing approach, and some of my experiences.
Little code per test
The biggest advantage of the approach, is that you tend to write very little unique code for each test. You generally access the application through a public interface as a user would, often a command line interface or (web)service call. You then create many tests by for example varying the command line options or request contents. This reduces test maintenance work, since you have less test code to worry about, and the public API of your program should change relatively infrequently.
Legacy code
Text-Based Testing is obviously a regression testing technique. You’re checking the code still does what it did before, by checking the log is the same. So these tests are perfect for refactoring. As you move around the code, the log statements move too, and your tests stay green, (so long as you don’t make any mistakes!) In most systems, it’s cheap and risk-free to add log statements, no matter how horribly gnarly the design is. So text-based testing is an easy way to get some initial tests in place to lean on while refactoring. I’ve used it this way fairly successfully to get legacy code under control, particularly if the code already produces a meaningful log or textual output.
No help with your design
I just told you how good Text-Based Testing is with Legacy code. But actually these tests give you very little help with the internal design of your program. With normal TDD, the activity of creating unit tests at least forces you to decompose your design into units, and if you do it well, you’ll find these tests giving you all sorts of feedback about your design. Text-Based tests don’t. Log statements don’t care if they’re in the middle of a long horrible method or if they’re spread around several smaller ones. So you have to get feedback on your design some other way.
I usually work with TDD at the unit level in combination with Text-Based tests at the functional level. I think it gives me the best of both worlds.
Log statements and readability
Some people complain that log statements reduce the readability of their code and don’t like to add any at all. They seem to be out of fashion, just like comments. The idea is that all the important ideas should be expressed in the class and method names, and logs and comments just clutter up the important stuff. I agree to an extent, you can definitely over-use logs and comments. I think a few well placed ones can make all the difference though. For Text-Based Testing purposes, you don’t want a log that is megabytes and megabytes of junk, listing every time you enter and leave every method, and the values of every variable. That’s going to seriously hinder your refactoring, apart from being a nightmare to store and update.
What we’re talking about here is targeted log statements at the points when something important happens, that we want to make sure should continue happening. You can think about it like the asserts you make in unit tests. You don’t assert everything, just what’s important. In my experience less than two percent of the lines of code end up being log statements, and if anything, they increase readability.
Text-Based tests are completed after the code
In normal TDD you write the test first, and thereby set up a mini pull system for the functionality you need. It’s lean, it forces you to focus on the problem you’re trying to solve before you solve it, and starts giving you feedback before you commit to an implementation. With Text-Based Testing, you often find it’s too much work the specify the log up front. It’s much easier to wait until you’ve implemented the feature, run the test, and save the log afterwards.
So your tests usually aren’t completed until after the code they test, unlike in normal TDD. Having said that, I would argue that you can still do a form of TDD with Text-Based Tests. I’d normally create the half the test before the code. I name the test, and find suitable inputs that should provoke the behaviour I need to implement in the system. The test will fail the first time I run it. In this way I think I get many of the benefits of TDD, but only actually pin down the exact assertion once the functionality is working.
“Expert Reads Output” Antipattern
If you’re relying on a diff in the logs to tell you when your program is broken, you had better have good logs! But who decides what to log? Who checks the “golden copy”? Usually it is the person creating the test, who should look through the log and check everything is in order the first time. Of course, after a test is created, every time it fails you have to make a decision whether to update the golden copy of the log. You might make a mistake. There’s a well known antipattern called “Expert Reads Output” which basically says that you shouldn’t rely on having someone check the results of your tests by eye.
This is actually a problem with any automated testing approach – someone has to make a judgement about what to do when a test fails – whether the test is wrong or there’s a bug in the application. With Text-Based Testing you might have a larger quantity of text to read through compared with other approaches, or maybe not. If you have human-readable, concise, targeted log statements and good tools for working with them, it goes a long way. You need a good diff tool, version control, and some way of grouping similar changes. It’s also useful to have some sanity checks. For example TextTest can easily search for regular expressions in the log and warn you if you try to save a golden copy containing a stack trace for example.
In my experience, you do need to update the golden copy quite often. I think this is one of the key skills with a Text-Based Testing approach. You have to learn to write good logs, and to be disciplined about either doing refactoring or adding functionality, not both at the same time. If you’re refactoring and the logs change, you need to be able to quickly recognize if it’s ok, or if you made a mistake. Similarly, if you add new functionality and no logs change, that could be a problem.
Agile Tests Manage Behaviour
When you create a unit test, you end with an Assert statement. This is supposed to be some kind of universal truth that should always be valid, or else there is a big problem. Particularly for functional level tests, it can be hard to find these kinds of invariants. What is correct today might be updated next week when the market moves or the product owner changes their mind. With Text-Based Testing you have an opportunity to quickly and easily update the golden copy every time the test “fails”. This makes your tests much more about keeping control of what your app does over time, and less about rewriting assert statements.
Text-Based Testing grew up in the domain of optimizing logistics planning. In this domain there is no “correct” answer you can predict in advance and assert. Planning problems that are interesting to solve are far too complex for a complete mathematical analysis, and the code relies on heuristics and fancy algorithms to come up with better and better solutions. So Text-Based Testing makes it easy to spot when the test produces a different plan from before, and use it as the new baseline if it’s an improvement.
I think generally it leads to more “agile” tests. They can easily respond to changes in the business requirements.
Conclusions
There is undoubtedly a lot more to be said about Text-Based Testing. I havn’t mentioned text-based mocking, data-driven vs workflow testing, or how to handle databases and GUIs – all relevant topics. I hope this article has given you a flavour of how it’s different from ordinary TDD, though. I’ve found that good tool support is pretty essential to making Text-Based Testing work well, and that it’s a particularly good technique for handling legacy code, although not exclusively. I like the approach because it minimizes the amount of code per test, and makes it easy to keep the tests in sync with the current behaviour of the system.





