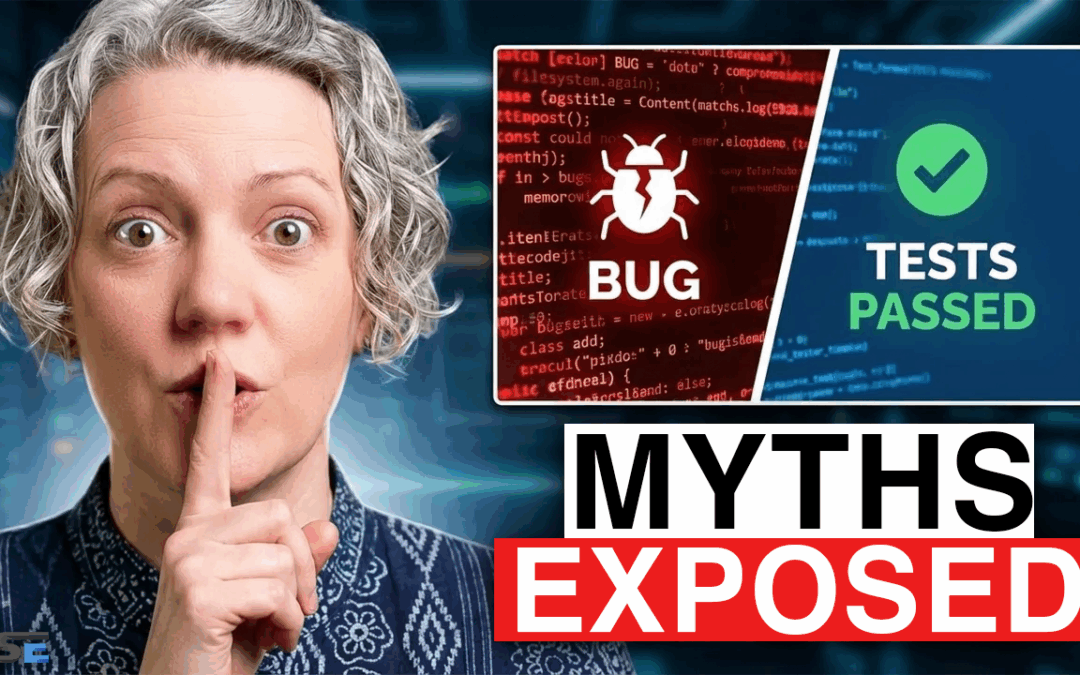
by Emily Bache | Mar 18, 2026 | Testing Strategy and Advice
This is a companion post to my video with the same title. Whether you’re using an AI tool to write them or not, you need tests. If you’re doing Continuous Delivery, the tests in your pipeline are essential to determine releasability. Unfortunately, it’s often a source...
by Emily Bache | Jan 2, 2018 | Experience Report
Fictitious people that might get real – and sue you! Finding realistic data for testing is often a headache, and a good strategy is often to fabricate it. But what if your randomly generated data turns out to belong to a real person? What if they complain and...
by Emily Bache | Aug 6, 2012 | Coding Skills
Please note – As of March 2013, I have rewritten this post in the light of further experience and discussions. The updated post is available here. I feel like I’ve spent most of my career learning how to write good automated tests in an agile environment....
by Emily Bache | Jun 22, 2011 | Experience Report
I’ve just spent 3 weeks teaching a class of 11 students about automated testing, as part of a one year course in software testing. The course is organized by the local “Kvalificerade Yrkes Högskolan”, KYH. (loosely translated: Skilled Trade...
by Emily Bache | Feb 21, 2010 | Coding Skills
In my current assignment, I’m taking the role of “developer-in-test”. I’m working in a large distributed development project, which is building new functionality on a large existing codebase. In practice, I work closely with the developers in...
