This Code Kata is included in my new book “The Coding Dojo Handbook”, currently published as a work-in-progress on LeanPub.com. You can also download starting code and these instructions from my github page.
As a Health Insurer,
I want to be able to search for patients who have a medicine clash,
So that I can alert their doctors and get their prescriptions changed.
Health Insurance companies don’t always get such good press, but in this case, they actually do have your best interests at heart. Some medicines interact in unfortunate ways when they get into your body at the same time, and your doctor isn’t always alert enough to spot the clash when writing your prescriptions. Sometimes, medicine interactions are only identified years after the medicines become widely used, and your doctor might not be completely up to date. Your Health Insurer certainly wants you to stay healthy, so discovering a customers has a medicine clash and getting it corrected is good for business, and good for you!
For this Kata, you have a recently discovered medicine clash, and you want to look through a database of patient medicine and prescription records, to find if any need to be alerted to the problem. Create a “Patient” class, with a method “Clash” that takes as arguments a list of medicines, and how many days before today to consider, (defaults to the last 90 days). It should return a collection of days on which all the medicines were being taken during this time.
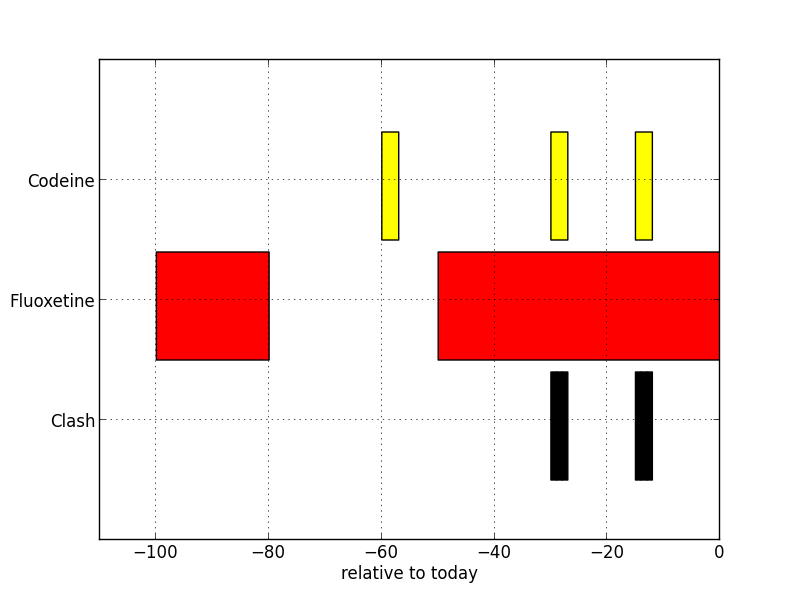
If you like, you can also create a visualization of the clash, something like this:
Data Format
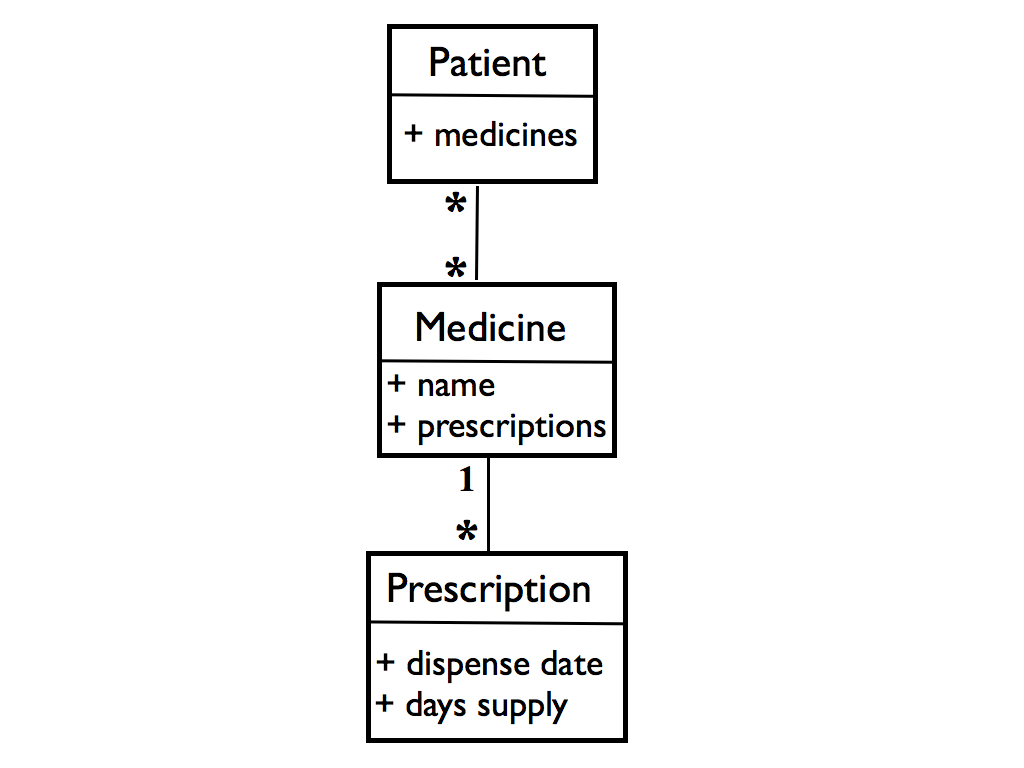
You can assume the data is in a database, which is accessed in the code via an object oriented domain model. The domain model is large and complex, but for this problem you can ignore all but the following entities and attributes:
In words, this shows that each Patient has a list of Medicines. Each Medicine has a list of Prescriptions. Each Prescription has a dispense date and a number of days supply.
You can assume:
- Patients start taking the medicine on the dispense date.
- The “days supply” tells you how many days they continue to take the medicine after the dispense date.
- If they have two overlapping prescriptions for the same medicine, they stop taking the earlier one. Imagine they have mislaid the medicine they got from the first prescription when they start on the second prescription.
When you’ve tried the Kata for yourself
Then you might be interested in reviewing the sample solution I’ve put up on my github page. I find this code interesting because it is seemingly well written. The methods are short with thought-through names, and there are lots of unit tests. I also find it very difficult to follow. What do you think?
The biology of medicine clashes*
When you take a pill of medicine, the active substance will be absorbed through the lining of the gut, and enter your bloodstream. That means it will be taken all over your body, and can do its work. For example, if you take a headache pill, the active substance in the drug will be taken by your blood to where it can block your pain receptors. At the same time, there are enzymes at work in your liver, which break down medicinal substances they find in your bloodstream. Eventually all the medicine will be removed, so you have to take another pill if you want the effects to continue.
In the liver, there are several different enzymes working, and they are specialized in breaking down different substances. For example, the “CYP 2C9” enzyme will break down ibuprofen, the active ingredient in many headache pills. The trouble is, there are other medicines which will stop particular enzymes from doing their work, which can lead to an overdose or other ill effects.
One example is the clash between fluoxetine and codeine. Fluoxetine is known by its trade name “Prozac”, and is often taken for depression. Codeine is another ingredient used in headache pills, and is actually a “pro-drug”, so it works slightly differently. Codeine needs to be broken down in the liver by the enzyme “CYP 2D6” into the active substance, morphine, before it will do anything. Fluoxetine has the effect of blocking “CYP 2D6”, so if you take the two medicines together, you won’t get much painkilling effect from the codeine. That could be depressing!
The solution to the problem is to take a different painkiller – one that’s not affected by that liver enzyme. Simply switch codeine for ibuprofen, and you should be be a little happier.
* With thanks to Sara Sjöberg for helping me with this section