In my last post, I started talking about London School TDD, and the two features of it that I think distinguish it from Classic TDD. The first was Outside-In development with Double Loop TDD, which I’d like to talk more about in this post. The second was “Tell, Don’t Ask” Object Oriented Design. I’ll take that topic up in my next post.
Double Loop TDD
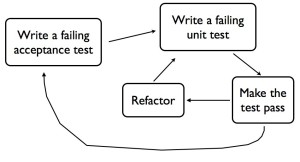
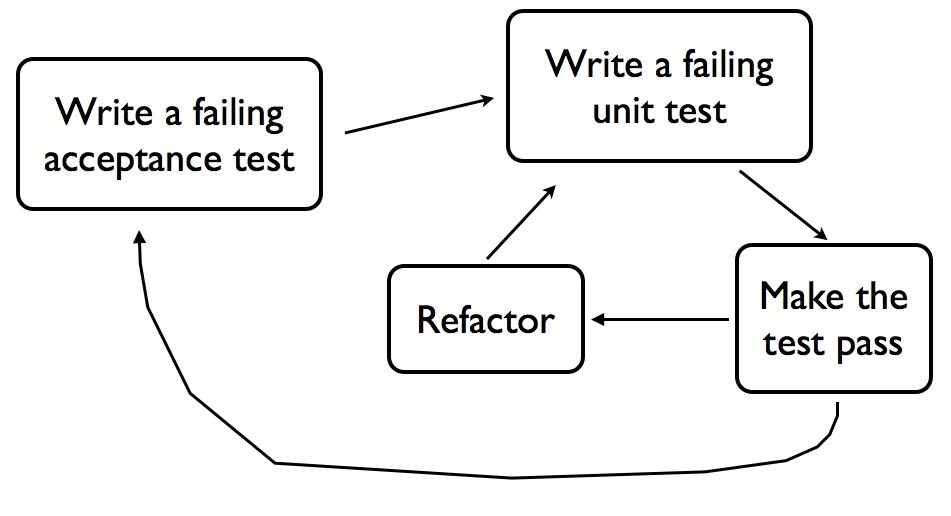
When you’re doing double loop TDD, you go around the inner loop on the timescale of minutes, and the outer loop on the timescale of hours to days. The outer loop tests are written from the perspective of the user of the system. They generally cover thick slices of functionality, deployed in a realistic environment, or something close to it. In my book I’ve called this kind of test a “Guiding Test”, but Freeman & Pryce call them “Acceptance Tests”. These tests should fail if something the customer cares about stops working – in other words they provide good regression protection. They also help document what the system does. (See also my article “Principles for Agile Automated Test Design“).
I don’t think Double Loop TDD is unique to the London School of TDD, I think Classic TDDers do it too. The idea is right there in Kent Beck’s first book about eXtreme Programming. What I think is different in London School, is designing Outside-In, and the use of mocks to enable this.
Designing Outside-In
If you’re doing double loop TDD, you’ll begin with a Guiding Test that expresses something about how a user wants to interact with your system. That test helps you identify the top level function or class that is the entry point to the desired functionality, that will be called first. Often it’s a widget in a GUI, a link on a webpage, or a command line flag.
With London School TDD, you’ll often start your inner loop TDD by designing the class or method that gets called by that widget in the GUI, that link on the webpage, or that command line flag. You should quickly discover that this new piece of code can’t implement the whole function by itself, but will need collaborating classes to get stuff done.
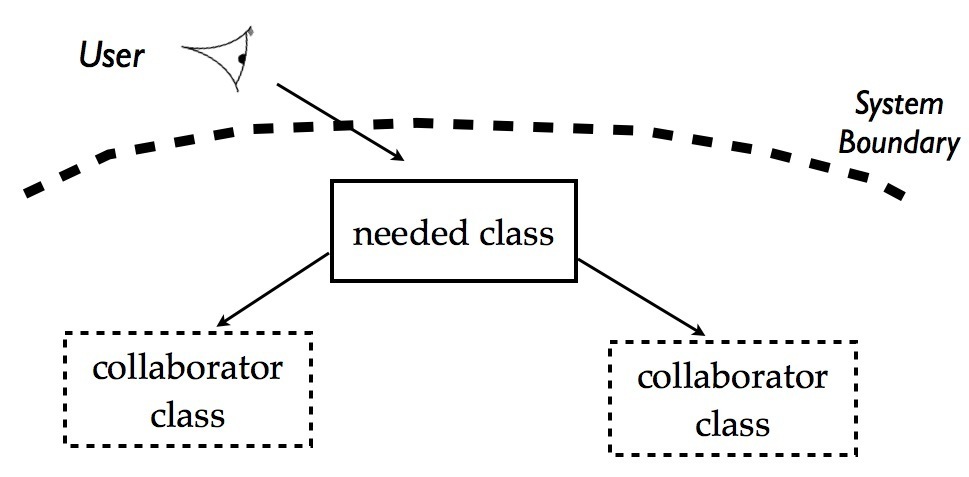
The user looks at the system, and wants some functionality. This implies a new class is needed at the boundary of the system. This class in turn needs collaborating classes that don’t yet exist.
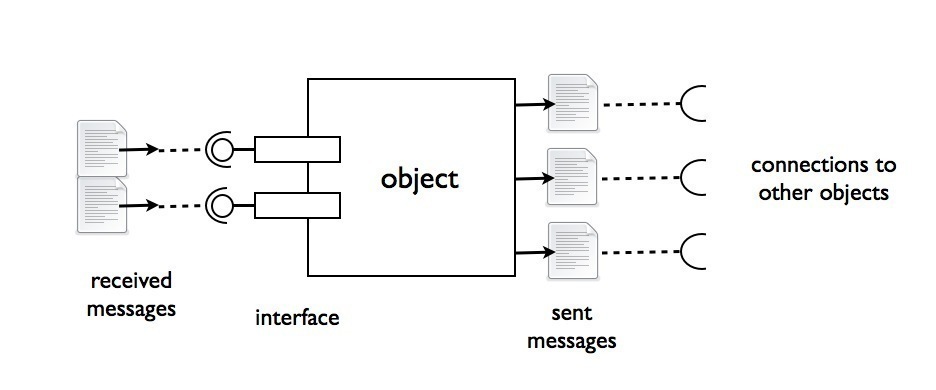
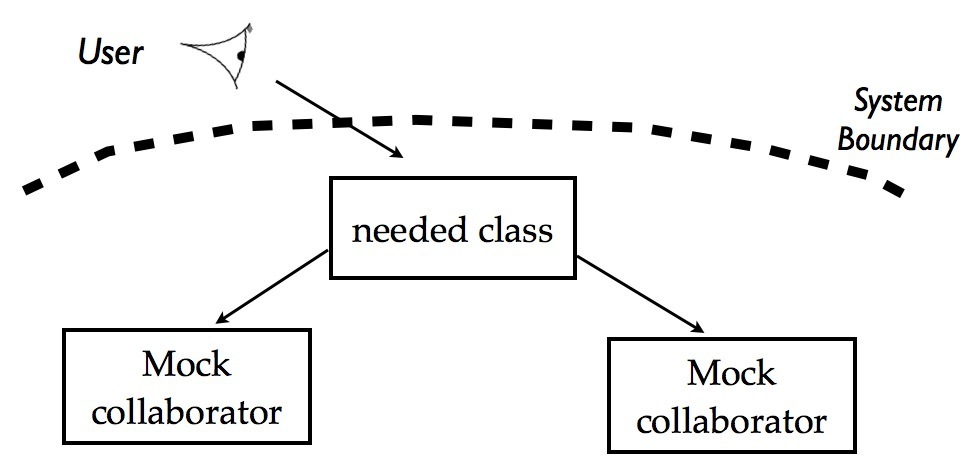
The collaborating classes don’t exist yet, or at least don’t provide all the functionality you need. Instead of going away and developing these collaborating classes straight away, you can just replace them with mocks in your test. It’s very cheap to change mocks and experiment until you get the the interface and the protocol just the way you want it. While you’re designing a test case, you’re also designing the production code.
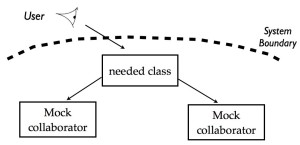
You replace collaborating objects with mocks so you can design the interface and protocol between them.
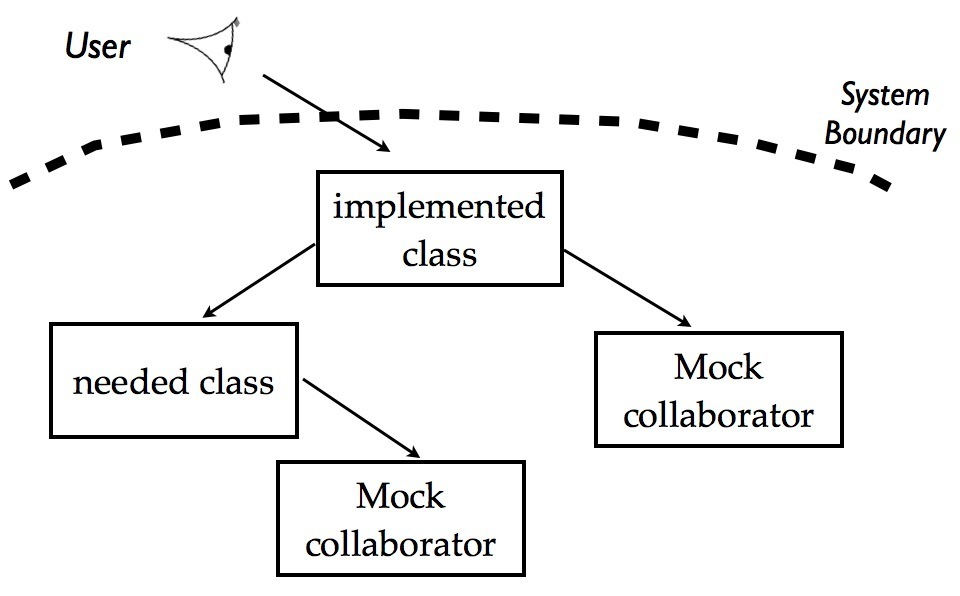
When you’re happy with your design, and your test passes, you can move down the stack and start working on developing the implementation of one of the collaborating classes. Of course, if this class in turn has other collaborators, you can replace them with mocks and design these interactions too. This approach continues all the way through the system, moving through architectural layers and levels of abstraction.
You’ve designed the class at the boundary of the system, and now you design one of the collaborating classes, replacing its collaborators with mocks.
This way of working lets you break a problem down into manageable pieces, and get each part specified and tested before you move onto the next part. You start with a focus on what the user needs, and build the system from the “outside-in”, following the user interaction through all the parts of the system until the guiding test passes. The Guiding Test will not usually replace parts of the system with mocks, so when it passes you should be confident you’ve remembered to actually implement all the needed collaborating classes.
Outside-In with Classic TDD
A Classic TDD approach may work outside-in too, but using an approach largely without mocks. There are various strategies to cope with the fact that collaborators don’t exist yet. One is to start with the degenerate case, where nothing much actually happens from the user’s point of view. It’s some kind of edge case where the output is much simpler than in the normal or happy-path case. It lets you build up the structure of the classes and methods needed for a simple version of the functionality, but with basically empty implementations, or simple faked return values. Once the whole structure is there, you flesh it out, perhaps working inside-out.
Another way to do this in Classic TDD is to start writing the tests from the outside-in, but when you discover you need a collaborating class to be implemented before the test will pass, comment out that test and move down to work on the collaborator instead. Eventually you find something you can implement with collaborators that already exist, then work your way up again.
A Classic TDD approach will often just not work outside-in at all. You start with one of the classes nearer the heart of the system. You’ll pick something that can be fully implemented and tested using collaborating classes that already exist. Often it’s a class in the central domain model of the application. When that is done, you continue to develop the system from the heart towards the outside, adding new classes that build on one another. Because you’re using classes that already exist, there is little need for using mocks. Eventually you find you’ve built all the functionality needed to get the Guiding Test to pass.
Pros and Cons
I think there’s a definite advantage to working outside-in, it keeps your focus on what the user really needs, and helps you to build something useful, without too much gold-plating. I think it takes skill and discipline to work this way with either Classic or London School. It’s not easy to see how to break down a piece of functionality into incremental pieces that you can develop and design step-by-step. If you work from the heart outwards, there is a danger you’ll build more than you need for what the user wants, or that you’ll get to the outside, discover it doesn’t “fit”, and have to refactor your work.
Assuming you are working outside-in, though, one difference seems to me to be in whether you write faked implementations in the actual production code, or in mocks. If you start with fakes in the production code, you’ll gradually replace them with real functionality. If you put all the faked functionality into mocks, they’ll live with the test code, and remain there when the real functionality is implemented. This could be useful for documentation, and will make your tests continue to execute really fast.
Having said that, there some debate about the maintainability of tests that use a lot of mocks. When the design changes, it can be prohibitive to update all the mocks as well as the production code. Once the real implementations are done, maybe the inner-loop tests should just be deleted? The Guiding Test could provide all the regression protection you need, and maybe the tests that helped you with your original design aren’t useful to keep? I don’t think it’s clear-cut actually. From talking to London School proponents, they don’t seem to delete all the tests that use mocks. They do delete some though.
I’m still trying to understand these issues and work out in what contexts London School TDD brings the most advantage. I hope I’ve outlined what I see as the differences in way of working with outside-in development. In my next post I look at how London School TDD promotes “Tell, Don’t Ask” Object Oriented Design.